
판다스 기초 - 10minutes to Pandas 따라하기
29 Oct 2018 | python pandas아래 내용들을 따라해보면서, 데이터 분석을 공부해보려고 한다!
- python 분석 실무, 유저 funnel 분석
- 파이썬으로 데이터 주무르기
- 2장 서울시 범죄 현황 분석
- 6장 19대 대선 결과 분석
- 8장 자연어 처리 시작하기
- 텍스트를 이용해 사용한 단어 빈도수, 감정 분석
그 전에 우선 문법을 간단히 리마인드할 목적으로 판다스를 공부하고, 나중에 새로 배운 것들을 계속 추가하자!!
실습파일보기
10 Minutes to pandas 1
1. Object Creation
list()함수는 텍스트 데이터를 하나씩 리스트로 만들어줌list('abcd')는['A', 'B', 'C', 'D']와 같음
2. 데이터 확인하기
해당 데이터를 간단하게 확인할 때 사용하기 유용하다.
- 속성(Attributes)
- .탭 (“데이터 이름”. 입력하고 탭 누름) : 속성값 알 수 있음
dir("데이터 이름"): 해당 데이터의 속성 출력하여 확인 가능.shape: 행,열을 출력해 데이터의 크기를 알 수 있음.index.columns.value
- 함수(Methods)
.head(): 앞쪽 데이터를 확인할 수 있음, 기본 5행이며 ()안에 행 수 입력 가능.tail(): 마지막쪽 데이터를 확인할 수 있음. 기본 5행이며 ()안에 행 수 입력 가능.info().describe(): 컬럼별 간단한 통계 정보, count, mean, std, min, 25%, 50% 75%, max- .
sort_index(axi=1, ascending=TRUE): 인덱스 정렬 .sort_values(by=''): 특정 컬럼의 정보로 정렬
- 속성과 함수의 차이
- 속성은 데이터를 갖게되면서 동시에 미리 계산되어 저장되어 있는 정보들
- 함수는 함수로 해당 데이터 타입에 따라 미리 지정되어 있는 함수(class 내 function을 method라고 함) 참고 : https://www.slideshare.net/dahlmoon/pythonnumpy-pandas-1
나중에 날짜형 데이터 다루는 ‘date_range’ 간단하게 알아보자
3. 데이터 선택하기
- object[‘칼럼’] , object[시작인덱스:끝인덱스+1], object[시작인덱스명:끝인덱스명]
.loc:이름 이용해서 선택하기.loc[인덱스명].loc[:, [칼럼명1,칼럼명2].loc[시작인덱스명:끝인덱스명, [칼럼명1, 칼럼명2]].loc[[인덱스명1, 인덱스명2],[칼럼명1, 칼럼명2]]: 인덱스와 칼럼 모두 원하는 값만 골라서 뽑아낼 수 있음
.iloc[]: 행렬 위치를 이용하여 선택하기.ix[]: 숫자와 이름 섞어서 사용할 때.ix[숫자, '칼럼명]: 해당 칼럼값을 하나씩 확인하면서 작업하는 경우 유용하게 사용할 수 있다.
# datatime의 형식일때 고르는 코드
df.loc[pd.to_datetime(['20181003', '20181005']), ['A','B']]
# A B
# 2018-10-03 0.208921 0.240602
# 2018-10-05 -0.393728 -1.232693
# 특정 칼럼값을 하나씩 확인하면서 정보 저장하는 코드
for i in range(len(df)-1):
if df.ix[i, 'sessionid'] == df.ix[i+1, 'sessionid']:
s.append(j)
else:
s.append(j)
j += 1
3-1. 조건을 이용하여 선택하기
- 데이터 각 값을 기준으로 : object>0
- 조건만 사용하면 조건이 맞는 값은 TRUE, 아닌 값은 FAlSE로 출력됨
- ojbject[조건] : 조건에 맞는 위치의 값이 나오고 그 외는 NaN으로 나옴
- 행의 값을 기준으로 : object.칼럼명 >0
- 조건만 사용하면 조건이 맞는 행은 TRUE, 아닌 행은 FAlSE로 출력됨
- ojbject[조건] : 조건에 맞는 행의 모든 칼럼 값이 노출됨
.isin([a,b]): 특정 값이 해당 데이터에 있는지 확인할 수 있다.
df[df>0]
df[df.A>0]
df2[df2['E'].isin(['two','four'])]
3-2. 데이터 선택하여 변경하기
- 레이블 이용해서 변경하기 :
df.at[dates[0],'A'] = 0 - 위치 이용해서 변경하기 :
df.iat[0,1] = 0 - array를 아예 변경하기 :
df.loc[:,'D'] = np.array([5] * len(df)) .loc[]도 특정 하나의 값을 지정할 수 있어서, 레이블/위치 이용해서 값을 바꾸는 것이 가능하다.
4. 결측값 (Missing data)
데이터 탐색을 하며 중요한 것 중 하나가 결측값의 여부를 확인하는 것이다. 그 결측값이 있는 데이터를 버릴지, 특정값으로 일괄적으로 넣을지 고민해야 한다.
.isna(): 결측값이면 TRUE를, 결측값이 아니면 FALSE를 출력하는 함수isna().sum()이렇게 사용해서 결측값의 갯수를 알아낼 수 있다.
.dropna(): 샘플수가 많다면 결측값이 있는 행을 삭제하는 것이 가능하다..dropna(): 결측치가 하나라도 있으면 버리는 코드.dropna(axis=1): col 중심으로 NA값 있으면 지운다. (default는 0, idex 기준으로 NA있는 row 지움).dropna(how='all'): 모든 값이 Null일 경우만 버리는 코드.dropna(thresh=2): 결측치가 두개 이상인 경우 버리는 코드.dropna(subset=['name', 'born']): 해당 column의 결측치가 있는 것을 선택하여 버리는 코드df[df.isnull().any(axis=1)]: 결측치가 하나 이상 있는 Case만 선택하는 코드
5. 운영(operation)
- 통계 정보 확인하기
.describe().mean().sub()를 이용해서 두 다른 데이터를 맞추기 위한 전 작업을 진행할 수 있음 ..(?)
- 함수 적용하기
.apply(np.cumsum): 누적합 계산.apply(lambda x: x.max()- x.min()): 새로운 함수 적용
5-1. Apply 함수 적용하기
데이터에 함수를 바로 적용하는 함수
df.apply(np.cumsum): 데이터 누적으로 계속 더해가는 코드df.apply(lambda x: x.max() - x.min()): 바로 적용하고 싶은 함수를 간단하게 만들어 적용함
5-2. 빈도(Histogramming)
s.value_counts(): 해당 값의 갯수를 구하는 코드, 가장 빈도가 높은 것부터 차근차근 나온다.
6. 합치기(Merge)
-
df['F'] = Series: 기존 데이터에 ‘F’ 칼럼이 없는 경우, 새로 지정하고 데이터를 넣으면 합치기 처럼 들어간다. pd.concat([A, B], axis= 0 or 1)- 다양한 타입 의 object를 합치는 기능
- aixis 0(default)이면 칼럼 중심으로, 1이면 인덱스 중심으로 합쳐짐
pd.merge(A, B, key=" ")- sql의 join과 비슷한 합치기 기능
- 특정 칼럼을 기준으로 두 데이터를 붙일 수 있음
A.append(B, ignore_index=TRUE or FALSE)- 열을 붙이는 기능
7. 그룹핑(Grouping)
그룹핑은 아래 절차를 포함하여 진행한다.
- 쪼개기(Splitting) : 데이터를 특정 기준에 의해 쪼개기
- 함수 적용하기(Applying) : 그룹별로 함수를 적용키기
-
결합하기(Combining) : 함수 적용한 결과를 결합하기
df.groupby('A').sum()- 해당 내용 항목별로 카테고리 묶음,숫자데이터 다른 칼럼 값끼리 더함
df.groupby('A').size()- 해당 내용 항목별로 카테고리 묶음, 그 사이즈 확인
- Series의
.value_counts()와 비슷
df.groupby('A')['B'].nunique()- ‘A’ 내용 항목별로 카테고리 묶고, 거기의 ‘B’ 유니크한 값 숫자 확인
df.groupby(['A', 'B')['C'].nunique().unstack()- ‘A’ 내용 항목별로 카테고리 묶고, ‘B’별로 ‘C’ 유니크한 값 숫자 확인
8. 변형하기(reshape)
- stact
- pivot_table
9. 시간 데이터(Time Series)
pd.to_datetime('A'): ‘A’값을 시간 데이터로 바꾸는 함수.resample('기준').함수(): 시간 간격 조절- 시간 구간이 작아지면 데이터 양이 증가한다고 해서 업-샘플링(up-sampling)이라 하고
- 시간 구간이 커지면 데이터 양이 감소한다고 해서 다운-샘플링(down-sampling)이라 함
ts.resample('5S').sum():5초 간격으로 값을 합치는 코드 -참고
- .to_period() :년/월, 년의 데이터로 변경
- .to_timestamp() : 년/월/시 데이터로 변경
10. 카테고리(Category)
11. 그래프 그리기(Plotting)
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns

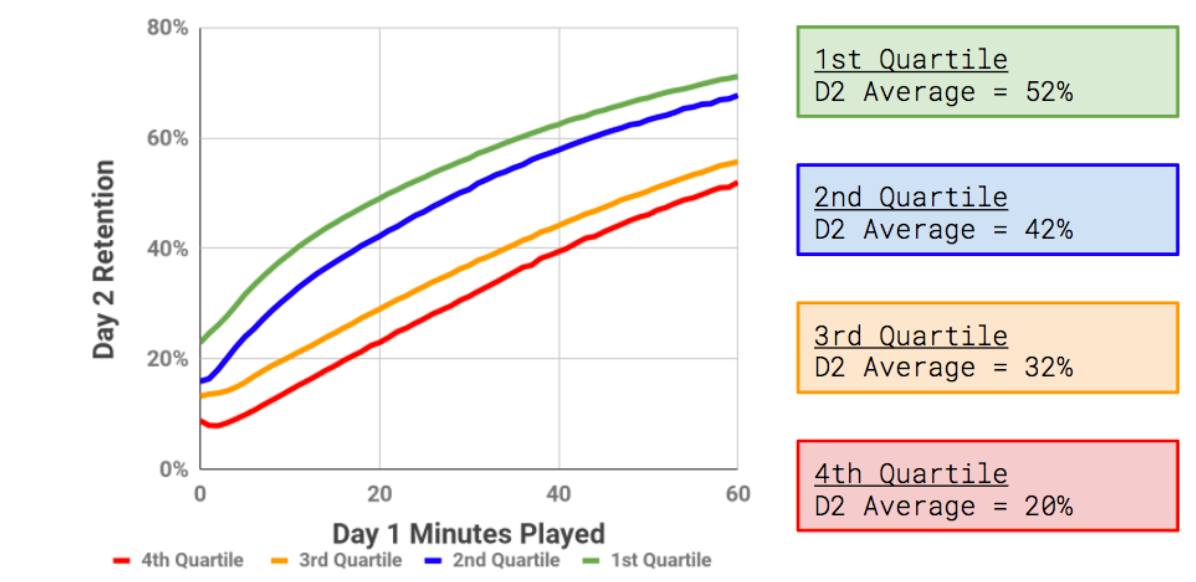 First time user experience가 중요,
First time user experience가 중요,  앞으로 고객이 얼마나 가치를 창출할까
앞으로 고객이 얼마나 가치를 창출할까  mattyford.com
mattyford.com