03 Jan 2019
|
떡국
유래
떡국
새해 첫날 장수와 재물복의 소망을 빌며, 떡국을 먹는 풍습이 있다. 떡국 떡의 원래 모습인 긴 가래떡은 ‘장수’를 상징하고 국 안에 썰어놓은 동전 모양의 둥근 떡은 ‘재물’이 들어오라는 의미한다.
궁중에서 먹던 떡국
왕실에서의 멥쌀과 찹쌀을 섞어 가래떡을 만들고 국물도 사골이나 양지머리 대신 묵은 닭과 꿩고기로 우려냈다.
꿩육수
- 꿩고기는 닭고기보다 육수가 으뜸이나, 훗날 구하기 어려워지자 서민들은 꿩대신 닭을 썼다. 이로인해 ‘꿩대신 닭’이라는 말이 유래 되었다.
- 고려 후기에 원나라의 풍속에서 배워온 매사냥이 귀족들의 사치스러운 놀이로 자리를 잡으면서 매가 물어온 꿩으로 국물을 만든 떡국이나 만둣국 그리고 꿩고기를 속으로 넣은 만두가 고급 음식으로 대접을 받았다. 하지만 특별하게 매사냥을 하지 않으면 꿩고기를 구하기가 쉬운 일이 아니어서 일반인들은 닭고기로 떡국의 국물을 내기도 했다. 그러나 오늘날 떡국의 국물은 꿩고기나 닭고기로 만들지 않고 쇠고기로 만든다. 쇠고기를 쉽게 구하게 된 이후에 생겨난 변화상이다. 한국민속대백과전
- 꿩 육수는 평양냉면에도 쓰인다. 평양냉면의 본고장 평안도에서는 정통 평양냉면 국물 중 꿩 육수를 최상위에 놓는다. 순수한 꿩 육수만을 사용하거나 쇠고기 육수에 꿩 육수를 가미해 맛을 돋우는 두 가지가 있는데 통틀어 꿩 육수라 부른다.
- 지난 남북정상회담에서 문재인 대통령이 방문했던 옥류관에서도 꿩과 닭을 이용해 육수를 낸다고 한다.[6]
원형가래떡
 출처
출처
- 가래떡을 써는 모양새도 어슷하지 않고 수저로 뜨기에 편리하도록 동전처럼 동그랗게 썰었다고 전해진다.
- 과거에는 떡국떡을 동그랗게 썰어 썼지, 타원형이 아니었다. 떡국떡을 동그랗게 자르지 않게 된 이유는 무엇일까. 궁중음식연구원 한복려 원장은 “직각보다 사선으로 칼질하기가 더 쉬운 데다, 어슷썰기로 하면 떡국떡이 훨씬 커져 푸짐한 느낌이 들기 때문 아닐까 싶다”고 말했다.
찹쌀과 멥쌀가루로 빚은 떡
- 멥쌀은 우리가 평소에 먹는 일반 보통쌀을 의미한다.
- 궁중에서 떡국은 ‘탕병’ 또는 ‘병탕’이라 하여 멥쌀과 찹쌀의 비율을 4:1로 섞어 가래떡을 만들어 매끈하고 찰진 식감을 살려 사용했다.
- 생반죽떡 가래떡이 없을 때 즉석에서 만들어 먹을 수 있는 떡으로 충청도 지방의 겨울철 별미다. 멥쌀가루와 찹쌀가루를 동량으로 익반죽한 뒤 동글게 빚어 납작하게 만든다. 생반죽떡은 가루가 고와서 오랫동안 반죽을 치대야 잘 풀어지지 않는다.
- 생떡국은 흰떡의 준비가 없을 때도 쌀가루만 준비되면 손쉽게 떡국을 끓일 수 있어 즉석음식인 동시에 별미음식이다. 쫄깃쫄깃하게 씹히는 가래떡과 달리 생떡은 마치 경단처럼 입 안에서 녹는다.
- 만드는 법
지역별 떡국
- 경상북도 ‘태양떡국’ : 떡국떡을 길쭉한 타원형이 아닌 태양처럼 둥글고 큰 모양으로 썰어 끓인 떡국으로, 육수가 아닌 장국으로 끓이는 특징이 있다. 육수로 만든 다른 떡국보다 훨씬 담백한 맛을 낸다.
- 전라도남도 ‘꿩떡국’ : 전라도의 떡국은 특이하게 꿩 육수를 사용하는데 사실 떡국의 원조는 바로 이 꿩 떡국입니다. 고서에 따르면 본래 궁중이나 양반 가의 떡국은 꿩고기를 우려서 만들었는데요, 꿩고기가 귀해지면서 평민들은 꿩 대신 닭고기를 사용해서 떡국을 끓였다고 합니다. 여기서 나온 속담이 바로 ‘꿩 대신 닭’이랍니다.
- 제주도 ‘몸떡국’ : 겨울철 별미 해초인 모자반으로 떡국을 만든다. 몸은 모자반의 사투리, 돼지등뼐르 우려낸 육수에 모자반과 떡, 메밀가루 등이 들어간다.
- 충청남도 ‘닭생떡국’ : 닭을 푹 삶아 거른 육수에 익반죽한 쌀가루 반죽을 가래떡 모양으로 만들어 썷어 넣고 닭고기 고명을 얹은 떡국입니다.
- 경상남도 ‘굽은떡국’ :떡국 떡은 대부분 길쭉한 타원 모양인데 여기 모가 난 떡국이 있습니다. 바로 경상도의 구운 떡국인데요. 특이하게 찹쌀과 멥살을 섞어 반죽한 떡을 판판하게 편 뒤 직사각형으로 잘라 구운 다음 멸치장국에 끓여 먹는 떡국입니다. 찹쌀떡 특유의 쫄깃함과 구운 떡의 독특한 식감이 특징입니다.
꿩 대신 닭
- 닭 농축 육수를 이용해 국물 맛이 깊은 떡국
궁중음식연구원에서 한국 음식을 가르치는 연구원 박준희 씨의 고향은 전라남도 해남이다. 해남에서는 주로 닭으로 육수를 낸다고. “일반적으로 닭 육수라 하면 닭 삶은 물을 말하지만, 저희 할머니나 어머니, 저는 다른 방법을 씁니다. 토막 낸 닭이 잠길 정도로 물을 부어 형체를 알아볼 수 없을 정도가 될 때까지 푹 끓이세요. 수분이 거의 날아가고 젤라틴이 생겨서 엉길 정도가 되면 불을 끕니다. 그리고 필요한 만큼만 따로 냄비에 덜어내어 거기에 물을 붓고 떡국을 끓이면 됩니다. 닭 농축 육수를 쓰면 맛이 한결 깊고 깔끔해요.” 이어서 그는 ‘닭 농축 육수는 200ml 우유팩에 담아 냉동실에 넣어두고 필요할 때마다 꺼내어 해동해 사용하면 편하다’고 덧붙였다.
- 진한 육수의 닭장떡국(https://www.wtable.net/recipes/n9ZSzyZEMLv9NF8MjsBCs9dx?r=)
- 닭 지식 : 닭은 이노신이라는 아미노산을 가지고 있다고 한다. 이노신은 다시마, 표고에 있는 글루탐산의 맛을 증폭시킨다. 백숙처럼 닭고기를 먹을 생각이라면. 끓는 육수에 닭을 투여하고 육수에 중점을 둘 계획이라면 차가운 물부터 닭을 투입한다.
13 Nov 2018
|
서비스기획
서비스 방향성
기능정의서
처음으로 혼자서 기획부터 진행하게 된 것이 앱 내 채팅 서비스였다. 이미 정해진 방향에 맞춰 스토리보드와 정책을 정리하는 것은 수월했는데, 처음부터 기획하자니 막막했다. 우선 서비스 방향성 부터 정리를 했다.
서비스 방향성
- “이런 서비스를 할 건데, 이러한 기능이 필요하다.”를 정의
- 서비스 기획자는 계속해서 서비스에 대해 설득을 해야 하는 롤을 가지고 있다.
- 따라서 아래와 같은 내용이 서비스 방향성 정의에 들어가는 것이 좋다.
- 서비스를 왜 해야 하는지 : 필요성
- 어떤 서비스를 할 것인지 : 정의
- 서비스의 목표은 무엇인지 : 목표
- 어떤 기능이 필요한지 : 기능 정의
- 그 기능들을 어떠한 순서로 어떻게 구현할지 : 스케쥴링
- 필요한 시간과 인력은 어떻게 드는지 : 리소스 플랜
같은 서비스더라도 방향에 따라 고객에게는 다른 가치를 제공하는 아예 다른 서비스가 된다. 사진 편집 서비스에서도 필터 기능에 집중한 것인지 아니면 상세한 수정에 집중한 것인지 등에 따라 다른 서비스가 된다. 우리가 하나의 사진 앱이 아닌 여러 사진 앱을 다운받고 사용하게 되는 이유이다. 그런데 정의와 목표를 정하려다보니 어렴풋이 생각하고 있는 것을 문장으로 표현하자니 머뭇거리게 되었다. 자꾸 채팅 서비스를 벗어나는 생각을 하게 되는 것 같아 망설여 졌다.
그렇게 막힐 때에는 스토리보드 먼저 그려봐요. 디스크립션까지 쓸 필요는 없고 머리에 있는 것을 구체적으로 그려본다는 마음으로요. 그러다 막히면 기능정의서로 정리해봐요.
그래서 스토리보드를 그려나갔더니 의외로 채팅 서비스라는 틀 안에서 내가 생각한 방향에 맞춰 적용할 수 있는 포인트들이 보였다. 그런데 상세하게 어떤 페이지에 어떤 기능이 필요한지 구체적으로 생각하지 않고 방향성을 어떻게 녹일지 고민하다보니 페이지를 확장하기가 애매했다. 그래서 기능정의서를 정리해보았다. 물론 기능정의서는 다양한 양식이 있지만 나는 우선 리스트로 정리하며 구조적인 것을 파악하고 정리하려고 했다.
기능정의서
- 우선 페이지를 리스트업 하고
- 그 페이지에 들어갈 요소들을 정리하고
- 그 요소들에 대한 필요 기능들을 하나씩 적는다.
- DB 연동 유무
- 관리자 페이지 설정 필요 유무
- 설정값 없을때 초기 설정값 등
- 공통적인 사항이나 기타 내용(alert 등)은 별도로 리스트하여 정리한다.
그리고 거기에 맞춰 스토리보드를 다시 그리면 좀더 수월하다. 사수님이 새로운 기획을 할 때마다 A4 용지 빼곡히 뭔가 일일이 적고 나서 스토리보드를 쫙 그리시던데 이게 그거였구나 싶다.
SUMMARY
- 서비스의 방향에 대해서는 우선 정의와 목표까지만 정리
- 그 이후 해당 서비스의 기능정의서를 하나씩 리스트업
- 벤치마킹할 서비스들을 보며 페이지의 구성, 기능 파악
- 우리 서비스의 필요 페이지를 쭉 나열하고 기능 상세화하기
- 더 추가로 필요한 기능에 대해서는 별도로 정의하기
- 그 기능에 맞춰 스토리보드 작성하기
03 Nov 2018
|
python
EDA
datetime
python 분석 실무, 유저 funnel 분석 따라 공부하기
- 데이터 불러오기
- 날짜 데이터 다루기
- 결측치 처리
- 예측 모델을 통한 결측치 처리
- 데이터 전처리
- EDA, 일별 주요 통계
EDA(탐색적 데이터 분석, Exploratory Data Analysis)
데이터 전처리를 마쳤다면, 데이터를 둘러보며 어떤 것이 의미있는 정보인지 확인해야 한다. 기본적으로 날짜데이터가 있는 경우는 날짜의 연도/월/일/요일 등 어떤 타입의 날짜 데이터와 연관성이 있는지 알아본다. 유저의 로그를 가지고 분석하는 경우 특정 행동끼리의 상관성도 살펴볼 수 있다.
여기에서는 아래와 같이 EDA를 진행한다.
- 일별 주요 통계 <- 이 글에서는 여기
- 변수별 특성
- 구간별 전환율(Funnel Analysis)
- 클러스터링
- 클러스터별 전환율 차이 파악
기본 트렌드 체크
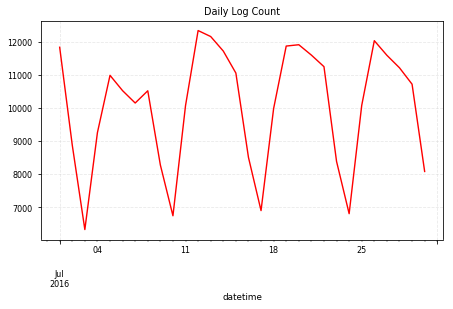
- 일별 로그 카운트 : 일별로 해당 액션이 일어난 수
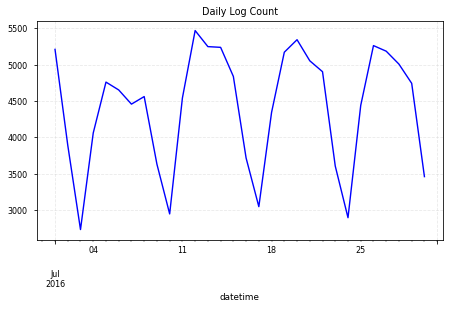
- 일별 세션 카운트 : 일별로 해당 액션을 한 유닉크 유저수
- 요일별 세션 카운트 : 요일별로 해당 액션을 한 유니크 유저수 트렌드
# daily log size
df.groupby('datetime').size().plot(c='r');
plt.title("Daily Log Count")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
# daily session counts => Active index
df.groupby('datetime')['sessionid'].nunique().plot(c='b');
plt.title("Daily Log Count")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
## daily session count (weekofday)
# 0: Monday, 6: Sunday
s = df.groupby("datetime")['sessionid'].nunique()
s.index = s.index.dayofweek # datetime 요일로 변환
s.plot(color='grey', kind='bar', rot=0);
plt.title("Daily Session")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
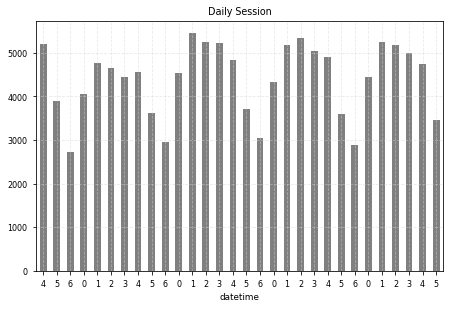 0: Monday, 6: Sunday
0: Monday, 6: Sunday
Note.
- 앱 로그에 sessionality 존재
- 로그 수와 세션수 트렌드가 유사
- 주말에 사용성이 매우 감소하고 주중 초반이 높은 편
- 문서앱이라는 특성상, 직장인 혹은 학생이 주로 사용할 것으로 가정하면 당연한 결과
해당 서비스에 맞는 일별 트렌드 확인
- 일별, 확장자별 로그수
- 일별, 위치별 로그수
- 일별, 액션별 로그수
- 일별, 화면 스크린별 유니크 유저수
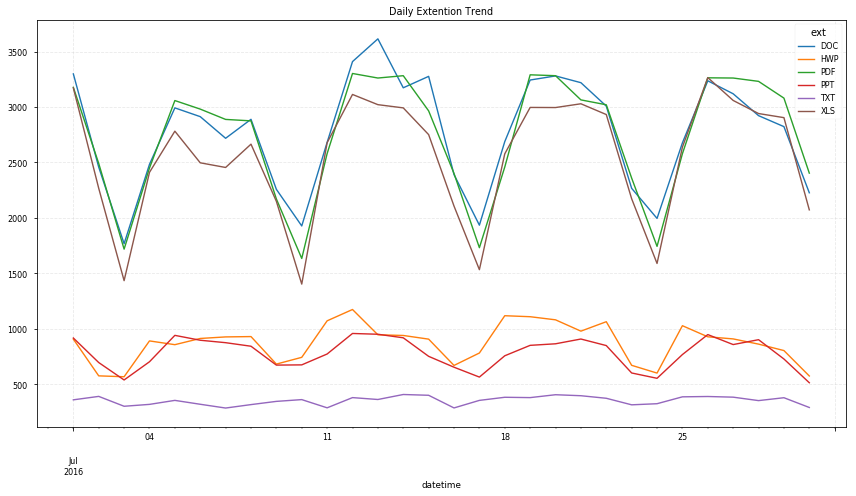
# daily trend by extention
df.groupby(['datetime', 'ext']).size().unstack().dropna(axis=1).plot(figsize=(12,7));
plt.title("Daily Extention Trend")
plt.grid(color = 'lightgrey', alpha=0.5, linestyle='--') # alpha는 투명도
plt.tight_layout()
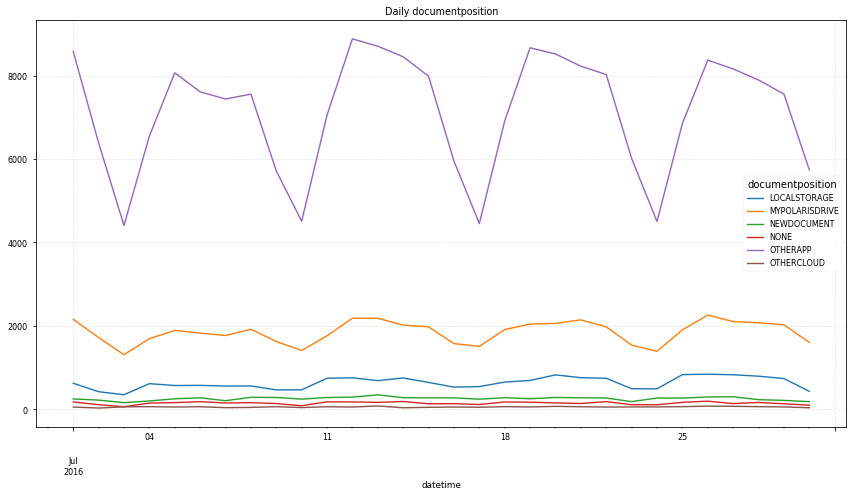
# daily trend by doc position
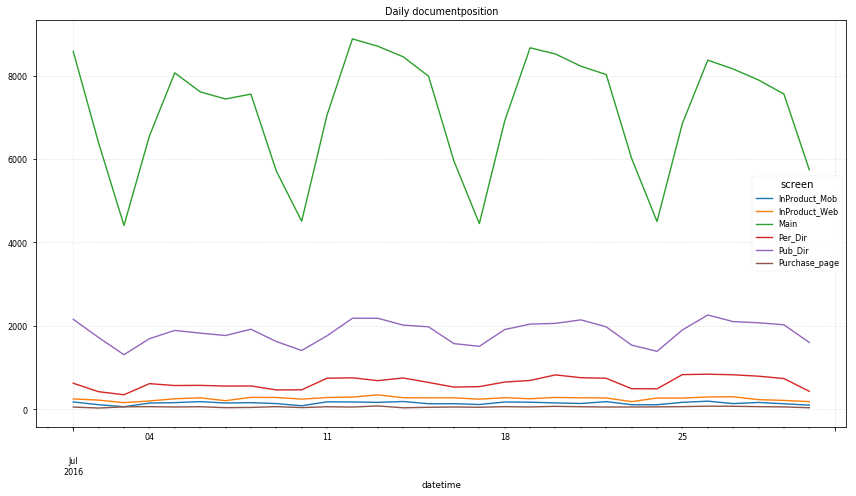
df.groupby(['datetime', 'documentposition']).size().unstack().dropna(axis=1).plot(figsize=(12, 7));
plt.title("Daily documentposition")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
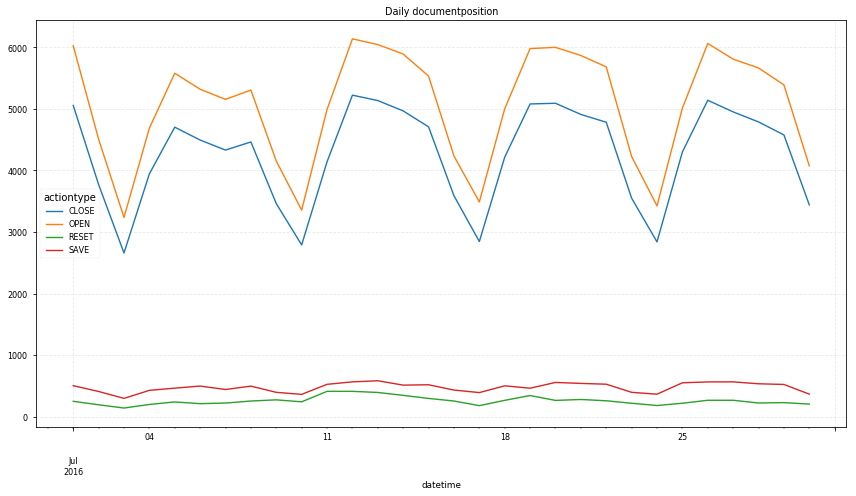
# daily trend by action type
df.groupby(['datetime', 'actiontype']).size().unstack().dropna(axis=1).plot(figsize=(12, 7));
plt.title("Daily documentposition")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
# daily trend by screen name
df.groupby(['datetime', 'screen']).size().unstack().dropna(axis=1).plot(figsize=(12, 7));
plt.title("Daily documentposition")
plt.grid(color='lightgrey', alpha=0.5, linestyle='--')
plt.tight_layout()
#heat map
screens = df.groupby(['datetime', 'screen'])['sessionid'].nunique().unstack().fillna(0).astype(int)
# cols order change
screens = screens[screens.mean().sort_values(ascending=False).index]
plt.subplots(figsize=(17,8))
sns.heatmap(screens, annot=True, fmt='d', annot_kws={'size':12}, cmap='Blues');
plt.title("screen count daily")
plt.tight_layout()
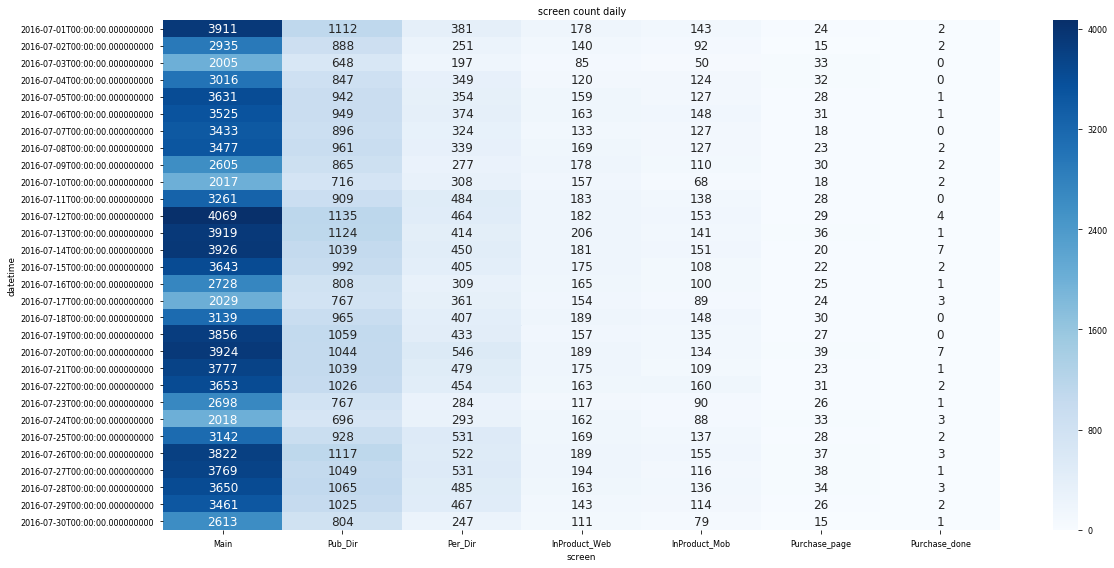
Note.
- doc, pdf, xls 순으로 주로 사용
- 주요 문서 이용 위치는 otherapp
- Main -> 구매완료(purchase_done) 까지 과정에서 대부분 이탈
이 글에서 사용한 Pandas 함수 정리
groupby()
특정 항목을 기준으로 갯수, 평균 등의 수치를 보고 싶을 때, 유용한 함수이다. 여기에서는 날짜별 로그수, 세션수 등을 봤다. plot()과 함께 쓰면, 따로 해당 데이터를 값으로 저장하지 않고 바로 경향성을 그래프로 확인할 수 있다.
.groupby([col1, col2]).apply() : 앞에 있는 칼럼으로 먼저 묶인다..groupby([col1, col2])['col3'].apply() : 구분은 col1, col2이지만, 값은 col3에 대한 걸 보고 싶을 때- apply 부분에 사용할 수 있는 함수들
plot()
pandas.DataFrame.plot에서 이번에 썼던 것만 봐보자.
.gird().title()tight_layout()- X(index),Y(column)으로 plotting
# groupby 이후에 unstack() 사용한 이유, X,Y 잡아주기
df.groupby(['datetime', 'ext']).size().unstack().dropna(axis=1).plot(figsize=(12,7));
sns.heatmap()
seaborn.heatmap를 한번 봐보자.
- parameters
annot : bool or rectangular dataset, optional
If True, write the data value in each cell. If an array-like with the same shape as data, then use this to annotate the heatmap instead of the raw data.
fmt : string, optional
sns.heatmap(screens, annot=True, fmt='d', annot_kws={'size':12}, cmap='Blues');
String formatting code to use when adding annotations.
annot_kws : dict of key, value mappings, optional, 값 텍스트 부분 설정
Keyword arguments for ax.text when annot is True.
포맷 코드로 숫자와 글 이용하기
Numbers formatting with
| Type |
Meaning |
| d |
Decimal integer |
| c |
Corresponding Unicode character |
| b |
Binary format |
| o |
Octal format |
| x |
Hexadecimal format (lower case) |
| X |
Hexadecimal format (upper case) |
| n |
Same as ‘d’. Except it uses current locale setting for number separator |
| e |
Exponential notation. (lowercase e) |
| E |
Exponential notation (uppercase E) |
| f |
Displays fixed point number (Default: 6) |
| F |
Same as ‘f’. Except displays ‘inf’ as ‘INF’ and ‘nan’ as ‘NAN’ |
| g |
General format. Rounds number to p significant digits. (Default precision: 6) |
| G |
Same as ‘g’. Except switches to ‘E’ if the number is large. |
| % |
Percentage. Multiples by 100 and puts % at the end. |